


Dimensional Reduction II
Understanding Yi Ma's Vision: Parsimony, Self-Consistency, and Closed-Loop Learning


The previous post, 'Dimensional Reduction, The Manifold and Sub-Manifold Hypotheses', introduced the fundamental concept of dimensionality reduction. As we've discussed, dimensionality reduction techniques are effective because most high-dimensional data is not inherently high-dimensional. Instead, it tends to reside on a lower-dimensional structure, as described by the manifold hypothesis.
Building on this foundation, we will now explore Yi Ma's insights regarding parsimony, self-consistency, and closed-loop transcription.
Understanding Yi Ma's Vision: Parsimony, Self-Consistency, and Closed-Loop Learning

Imagine you’re trying to learn about the world. You see lots of things—cats, dogs, trees—but your brain can’t remember every single detail of every object. Instead, it learns simple patterns (like "cats have pointy ears and whiskers") to recognize things quickly. This is the Principle of Parsimony: "Keep it simple, but not too simple!"
Now, how do you know your simple patterns are correct? You check! If you draw a cat based on your memory, you compare it to a real cat. If it looks wrong, you fix it. This is the Principle of Self-Consistency: "Make sure what you learn matches what you see!"
Closed-loop transcription ties these together. It’s like a conversation between two people: one compresses the data (“I see a cat”), the other reconstructs it (“Here’s what I think the cat looks like”). They play a game: The generator tries to fool the checker, and the checker tries to catch mistakes. Over time, both get better!
This loop ensures the system doesn’t just memorize, it understands.
One important characteristic of the close-loop transcription method is how the self-consistency verification is done.
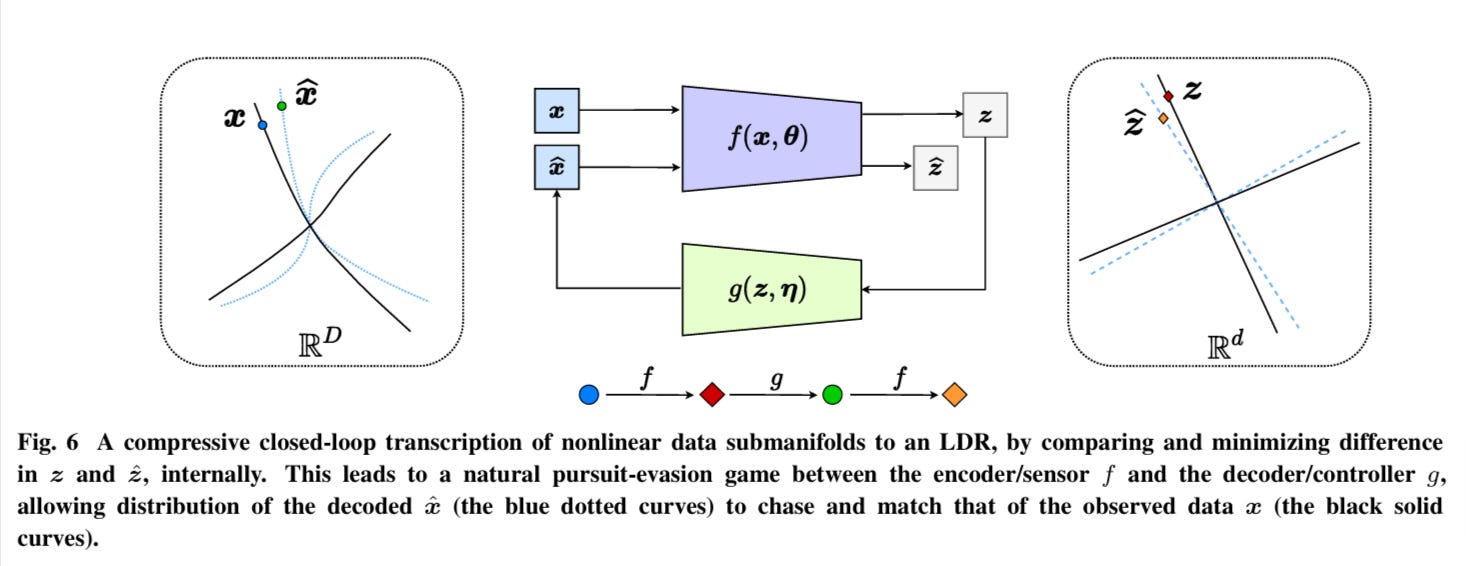
Here x is an input in the input space R^D, z is the encoded representation in the latent space R^d, with D » d. The function f is the encoder and sensor, g is the decoder.
After z=f(x) is executed,
g(f(x)) = g(z) =x^ is the reconstructed input.
But instead of comparing x and x^, which would be computationally intractable,
z is compared to f(g(f(x))) = z^, which is much simpler.
In this way, computing the Kullback-Leibler (KL) divergence for two probability distributions can be avoided.
Yi Ma credited the inspiration about closed-loop transcription to Norbert Wiener’s Cybernetics:

Contrasting Approaches: Autoencoders, GANs, and Closed-Loop
To see what makes Yi Ma’s ideas unique, let’s compare them to two popular methods.
1. Autoencoders: The Simplifiers
Autoencoders are like artists who sketch rough drafts. They take data (e.g., images), simplify it into a basic outline (latent code), then try to redraw the original from that outline. Their goal is to make the redrawn version as close as possible to the original.
2. GANs: The Art Forgers
GANs pit two networks against each other: one creates fake data (generator), and the other sniffs out fakes (discriminator). Over time, the generator gets so good that even the discriminator can’t tell real from fake.
3. Closed-Loop Transcription: The Librarian
Yi Ma’s method is like a meticulous librarian. It doesn’t just compress data—it catalogs it into labeled sections, checks that the labels match the contents, and fixes errors through feedback.
Key Differences:
Closed-loop Transcription:
Structure: Data isn’t just compressed—it’s grouped into clear categories (e.g., cat subspace vs. dog subspace). It is not satisfied with black boxes, instead tries to find white-boxes.
Feedback Loop: The system cross-checks its work, ensuring the compressed version can faithfully rebuild the original.
Sparsity: Like a minimalist, it uses only the essentials—no redundant details.
Conclusions
Dimensionality reduction achieves more than simple compression. It necessitates a balance between compressing information into a lower-dimensional space and reliably decompressing it back to a meaningful representation. As Lao Tzu observed, "That which shrinks must first expand," a principle embodied by our closed-loop transcription method. This method functions as an iterative process: one component maximizes compression, while the other minimizes information loss during decompression. Throughout this iterative loop, the system adheres to the constraint of representing information as a mixture of low-dimensional sub-manifolds ("white boxes") in the latent space. This careful mapping process ensures that essential meaning is preserved throughout the reduction and reconstruction steps.