
The Wiki That Thinks: Ingest, Lint, and the Question of What Knowledge Is For
And the Problems LLM Wikis are facing

There is a filing clerk and there is a librarian. The filing clerk takes documents as they arrive, assigns each one a number, and puts it in a drawer. The librarian reads the document, then walks the stacks and updates everything the document changes. The filing clerk is faster. The librarian is rarer.
Most software systems we build are filing clerks. Recently, AI researcher Andrej Karpathy published a GitHub Gist proposing an “LLM Wiki” (sometimes also called Karpathy’s second brain😄)—a deceptively simple design pattern where an AI doesn’t just passively retrieve documents, but actively maintains and edits a living repository of markdown files. In Karpathy’s setup, a human uses a frontend like Obsidian to browse, while a background coding agent like Claude Code acts as a tireless system maintainer. It is an attempt to build a librarian.
The distinction sounds minor. It isn’t. A filing clerk’s archive grows by accumulation. A librarian’s archive grows by integration. Those are fundamentally different things, and the difference becomes visible the moment you ask a question that cuts across more than one drawer.
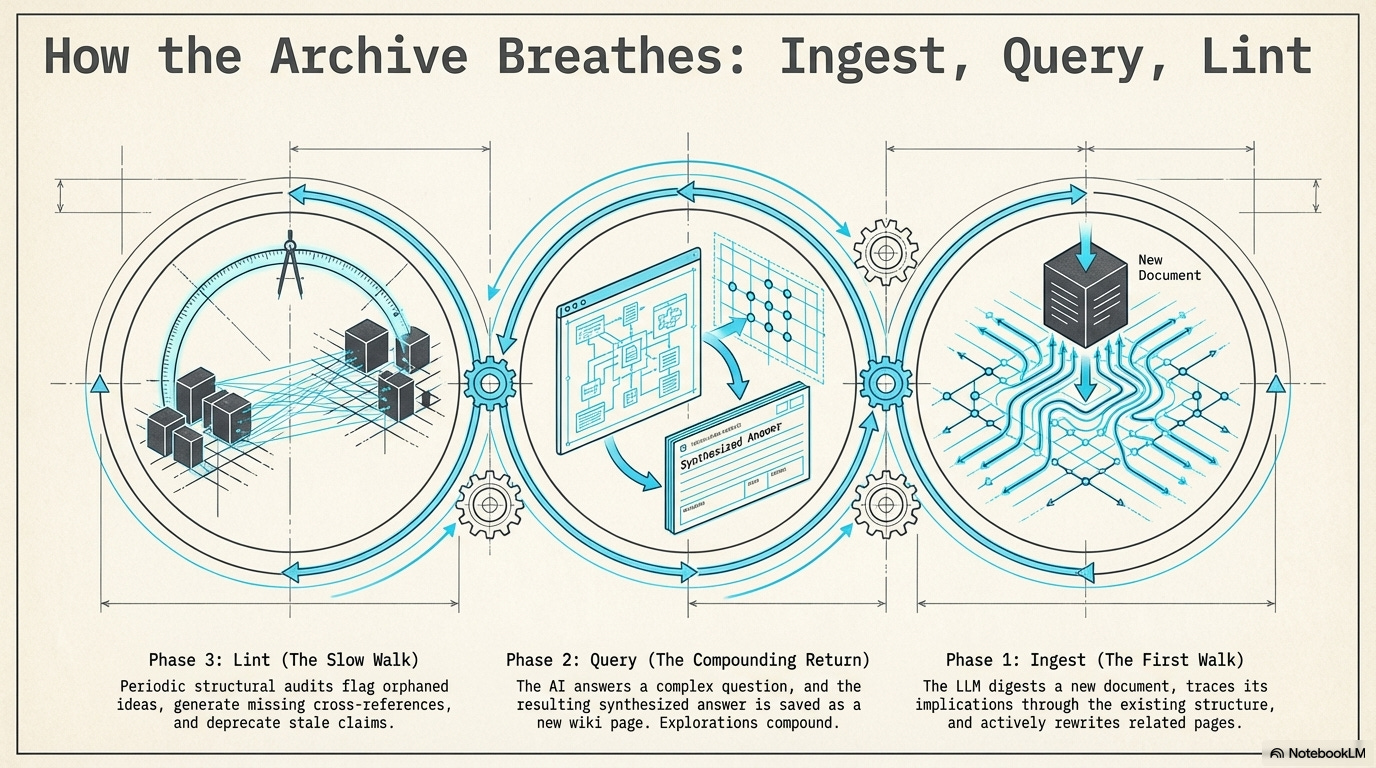
I. Ingest: The Librarian’s First Walk
Consider a technology company whose engineers maintain an internal wiki about their systems. The wiki has pages for every major service: the authentication service, the payment processor, the notification system. Each page describes its component accurately in isolation.
Now a new postmortem document arrives. There was an outage. The root cause analysis reveals something unexpected: when the payment processor retries a failed transaction, it triggers the notification system to send a receipt email — but the authentication service treats the retry as a new session and rate-limits it. The combination produces failures that none of the individual pages would predict.
A filing clerk processes this document. It goes into a folder labeled “Postmortems.” The three component pages remain unchanged. The next engineer who reads the authentication page learns nothing about what happens when it meets the payment processor under retry pressure.
An ingest operation does something different. The LLM reads the postmortem, then reads the existing pages simultaneously. It asks: what does this document change about what we know? The authentication page gets a warning about the edge case. The payment processor page gets an update to its retry logic. And possibly a new page is created: Cross-service failure modes under retry pressure — a concept that no single source document named, but which the act of reading them together made visible.
This is what ingest means. Not filing but rewriting. Each new document is digested — its implications traced through the existing structure and absorbed into it. Karpathy defines a strict division of labor for this: humans source the information; the LLM does the bookkeeping. The postmortem doesn’t sit in a drawer. It lives in the updated pages and new cross-references.
The epistemological parallel is exact. When you learn something genuinely new, you do not simply add it to a list. You revise. Learning that doesn’t revise is not learning — it’s accumulation, which is not the same thing.
II. Lint: The Editor’s Slow Walk
Ingest handles the moment of arrival. Lint handles everything that happens afterward.
A knowledge base degrades because the world moves. A page written two years ago may have been accurate then, but pages written since may have quietly superseded it. The old page sits there, still shaping answers, confident about things that are no longer true.
Here is a concrete example. The Wikipedia article on machine learning in 2012 described neural networks as “computationally expensive and difficult to train.” By 2017 the article had new sections on deep learning, but the original introduction was never revised. A reader scanning the top got 2012 knowledge; a reader scrolling further got 2017 knowledge. The article was internally inconsistent because everyone was writing their section, not auditing the whole.
Lint is the audit. It runs periodically, surveying the knowledge base for the structural problems that accumulate silently over time.
The most basic thing lint finds is orphan pages. Every orphan represents knowledge that cannot be reached. An orphan page is not wrong; it is invisible, which is operationally the same thing.
The more interesting thing lint finds is missing connections. Suppose a wiki about epistemology has a page on Gettier problems (whether justified true belief is sufficient for knowledge) and a separate page on reliability theory. Neither links to the other. But reliability theory was largely a response to Gettier. Lint reads both pages in the same context window, notices the conceptual proximity, and generates a missing link characterizing why the pages are related. The wiki knows something after lint runs that it did not know before.
This is lint at its most generative. It is not error-correction but structure-completion. And then there is contradiction detection, which is the hardest function and the one that matters most for the problem we are about to discuss.
III. The Error That Travels and the Danger of Overwriting
The filing clerk’s archive has a comforting property: it cannot lie. If a document is wrong, the wrongness is contained in that document.
The librarian’s archive does not have this property. When a document is wrong and its claims are integrated into other pages, the wrongness spreads. And it spreads in a specific way that makes it progressively harder to detect: it becomes consistent.
Suppose a wiki has a page describing SHA-256 as an appropriate algorithm for password hashing—a dangerous misconception, as fast hashing allows attackers to try billions of guesses per second. The error is ingested. The authentication best practices page is updated to link to the SHA-256 page. The user account security page is written by reading the authentication page. Four pages now describe SHA-256 as appropriate. They are mutually consistent. They all cite each other.
Now lint runs. It will not find a contradiction because the pages agree. The wiki has achieved false coherence: internal consistency around a false belief.
Karpathy’s architecture anticipates this exact danger by mandating a strict Three-Layer Architecture. In his system, the LLM Wiki must consist of:
Raw Sources (Immutable): The original PDFs and articles. The LLM reads these but is forbidden from modifying them. They are ground truth.
The Wiki (LLM-Maintained): The synthesized markdown files, generated by the LLM.
The Schema: The system rules dictating formatting and behavior.
The immutable raw layer is a vital defense. Information theory’s data processing inequality states that no post-processing of data can increase its mutual information with the original source. Each act of synthesis can only reduce or preserve ground truth; it cannot add it. If an LLM Wiki operates primarily on its own compiled pages rather than continually re-anchoring to its immutable sources, it drifts toward a stable false equilibrium.
But there is a deeper problem with how LLMs naturally want to manage that middle layer: they want to overwrite. When the LLM finds new information, its instinct is to erase the old text and replace it with a seamless, updated narrative.
A software engineer will immediately point out that if the Wiki is backed by version control like Git, nothing is truly lost. The old text is saved in the commit history. But Git preserves technical state, hidden in a log. If a user (or an LLM agent) reads the current wiki page, they only see the sanitized present. They see the result of the learning, but the process and the friction are invisible.
Here, we must look to the ultimate manual predecessor of the LLM Wiki: Niklas Luhmann’s Zettelkasten (slip-box). Luhmann built a legendary, hyper-linked paper knowledge system. But his method of updating was fundamentally different from a modern LLM. Luhmann almost never rewrote a card. His system was append-only.
If Luhmann wrote Card 21/3 stating a specific theory, and five years later read a book debunking it, he didn’t erase Card 21/3 and hide it in an archive. He created Card 21/3a, placed it directly behind the old one, and explicitly noted the contradiction in the text itself. He didn’t just update the facts; he documented the evolution of thought.
An LLM Wiki that silently overwrites state—even if Git remembers the change—destroys semantic provenance in the reading experience. To safely dislodge a propagated error and prevent it from recurring, the system must maintain the historical friction that Luhmann mastered. It must append updates directly into the narrative (”Update Oct 2026: Based on new source X, we no longer recommend...”) rather than continuously sanitizing the text to present a perfectly coherent, ahistorical present.
IV. Compounding Toward What?
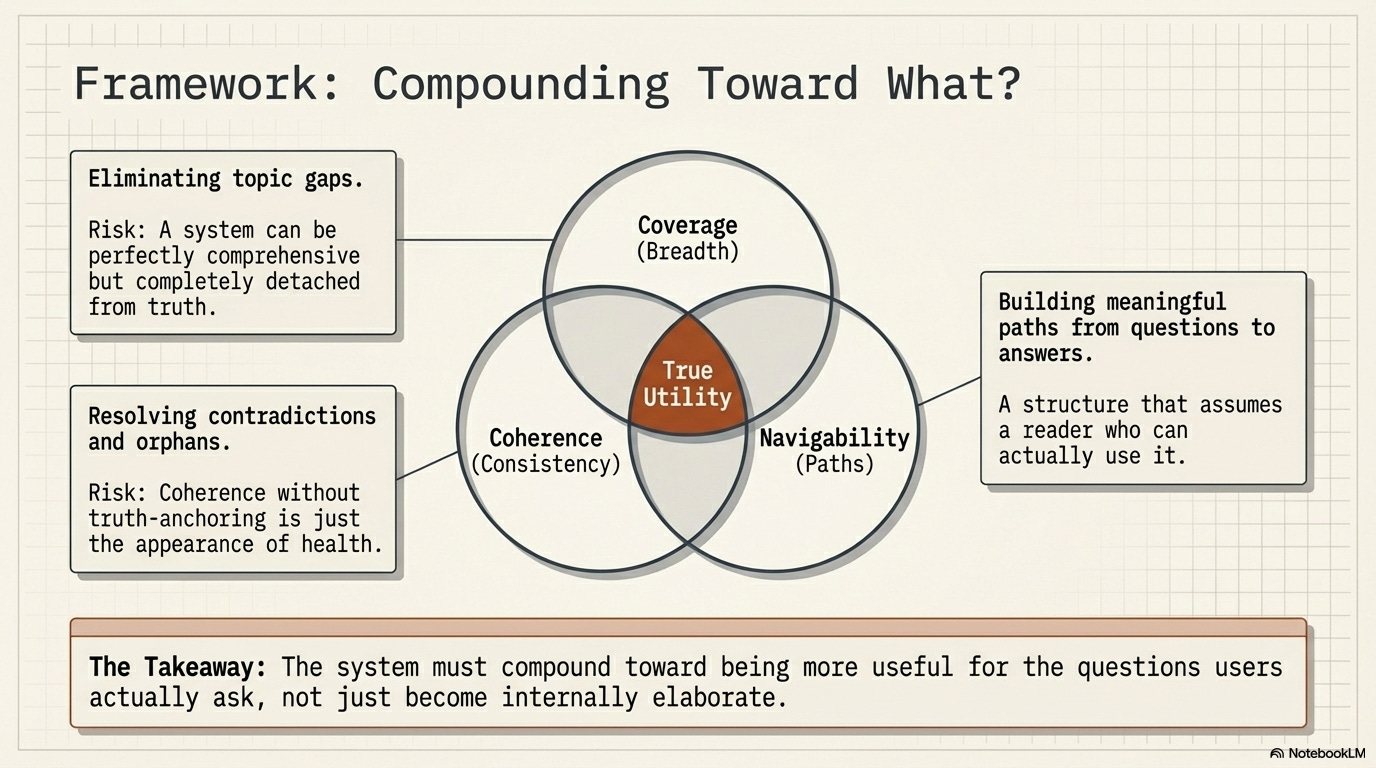
The standard pitch for the LLM Wiki is that it creates compounding value. The wiki grows smarter over time, not just larger. But what does a wiki compound toward? What does a maximally compounded wiki look like?
One answer: the wiki compounds toward coverage. A perfectly compounded wiki would have a page for every concept. But coverage alone is insufficient. A wiki can have complete coverage and still be shallow or wrong, measuring breadth over depth.
A second answer: the wiki compounds toward coherence. A perfectly compounded wiki would have no contradictions and no orphans. But as we’ve seen, coherence can be achieved through false consistency. Coherence in the absence of truth-anchoring is just the appearance of health.
A third answer: the wiki compounds toward navigability. The value of a knowledge base is in the paths it supports. A question arrives, and the wiki takes you from the question to the answer through a sequence of meaningful steps.
Navigability reveals an ultimate interface tension: who exactly is navigating this wiki? If a human is exploring the Wiki through Obsidian, the pages need narrative flow. If an LLM agent is reading the Wiki to answer a prompt, it needs dense metadata and strict semantic linking. The wiki should compound in the direction of becoming more useful for the questions its users actually ask, not just more internally elaborate.
V. The Ghost of the Librarian
The deepest thing Karpathy’s design captures is something that information retrieval has mostly ignored: knowledge is not a collection of true statements. It is a structure of relationships. You can have every relevant document and still know nothing, if you cannot navigate between them.
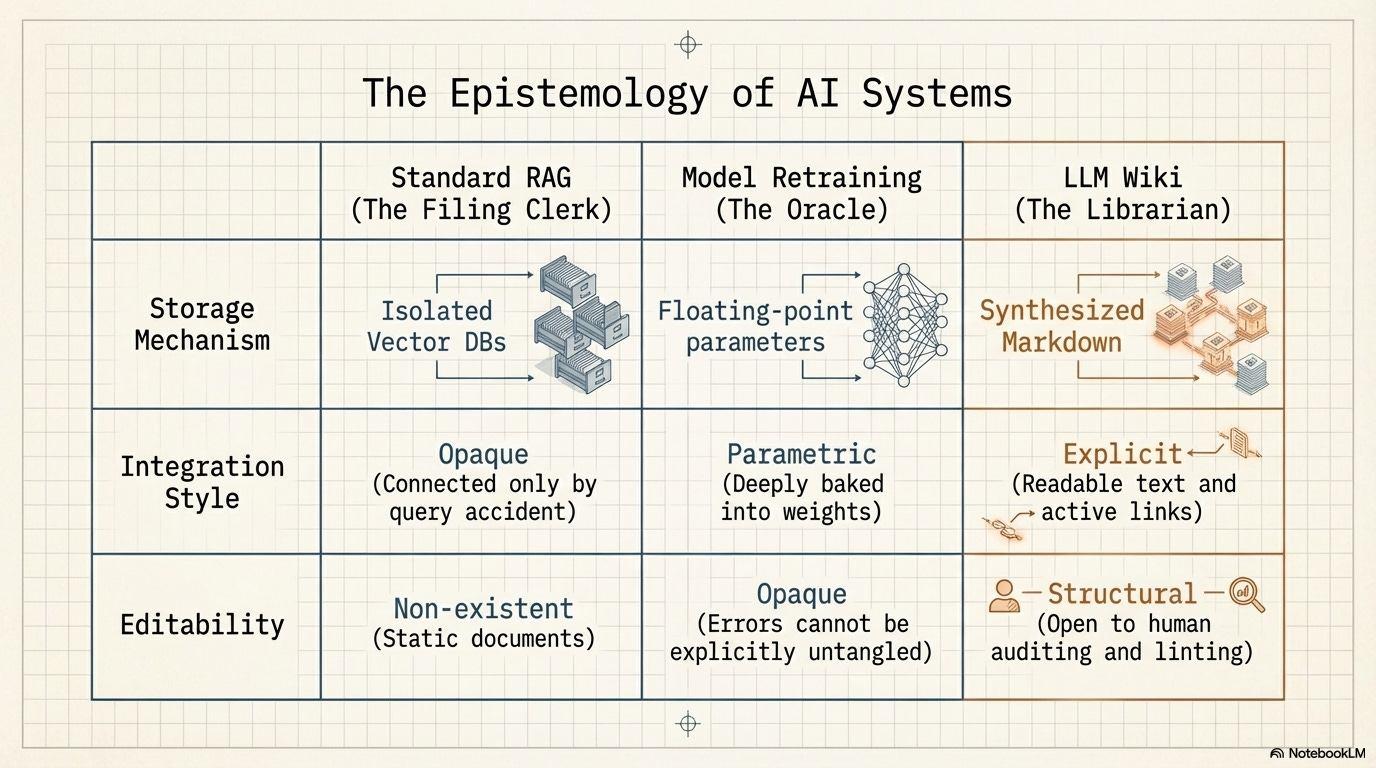
Current Retrieval-Augmented Generation (RAG) systems treat knowledge as a collection. The documents exist in isolation, connected only by the accident of being retrieved together in response to the same query. Every query starts from scratch. Standard RAG is the ultimate filing clerk.
There is, of course, another way to update what an AI knows: you can retrain the underlying model from scratch on the new material. When a model is retrained, it certainly integrates the new documents; its internal weights shift considerably to reflect the new concepts. It is the ultimate Oracle. But this integration is entirely opaque. It is parametric, not explicit. If an error like the SHA-256 fallacy is baked into a model’s weights during training, there is no page to edit, no cross-reference to untangle, no historical card to append a correction to. You cannot “lint” a neural network’s weights. You just have to hope you can fine-tune the error out of it later.
The LLM Wiki proposes a radical middle ground. It treats knowledge as an explicit structure. Documents are not just stored in a vector database (like RAG), nor are they dissolved into opaque floating-point numbers (like retraining). They are digested into readable, editable text. The relationships are made explicit. The structure grows more useful with every ingest and lint operation.
The problem with the librarian’s approach — error propagation, the temptation of destructive overwriting, the necessity of an immutable source layer — are real problems. They are the hard problems that any serious attempt to build a librarian will have to solve. The filing clerk doesn’t have these problems only because the filing clerk never attempts integration in the first place. The absence of ambition is not the same as correctness.
A knowledge base that compounds toward coverage, coherence, and navigability, while continuously appending context and re-anchoring against immutable sources, is not a solved system. But it is the right problem. The LLM Wiki is the most concrete proposal yet for what building a librarian might actually look like — not a metaphor for what AI should aspire to, but an implementation of it, with all the difficulties that implementation makes visible.
Words I've used several times to refer to defence against the overwriting problem: append-only, a *ledger* of discourse, and relational connection between claims.
Maintaining the *structure* of arguments and how they relate means it's all but impossible, once you encounter evidence debunking the usefulness of SHA-256 for password hashing, to propagate that misconception. The new ingest - "SHA-256 can be attacked by..." - is relationally entangled with whatever other claims and conclusions rest on the earlier mistaken claims. You immediately know what needs touching.
Importantly, you don't need to rely on the happenstance of any given person or LM simultaneously having those in context at the same time. Structure, relational and living map over a topic's discourse, forces this discipline.