
Building a Local Knowledge Base in Google's Open Knowledge Format (OKF)
Using Nous Hermes and Xiaomi Mimo LLM

From Karpathy’s LLM Wiki to Google’s Open Knowledge Format — a story about compounding knowledge with Hermes Agent by Nous Research — a desktop AI agent that can read files, run terminal commands, browse the web, and build things. The model behind it was Mimo V2.5 Pro by Xiaomi.
Karpathy’s proposal was simple and powerful: instead of dumping knowledge into a vector database and hoping retrieval-augmented generation rediscovers it each time, compile knowledge into interlinked markdown files. Write it once. Cross-reference it. Keep it current. Let the knowledge compound.
The spec called for three layers:
Raw sources — immutable copies of ingested material (articles, papers, transcripts)
Wiki pages — agent-owned markdown files for entities, concepts, and comparisons
The schema — a living document defining conventions, tag taxonomy, and quality standards
No database. No special tooling. Just a directory of .md files with YAML frontmatter and [[wikilinks]] between pages.
The agent created the full directory structure in seconds:
C:\LLMwiki\
├── SCHEMA.md
├── index.md
├── log.md
├── raw/{articles,papers,transcripts,assets}
├── entities/
├── concepts/
├── comparisons/
└── queries/
The schema was tuned for the AI/ML domain — tags for models, architectures, training techniques, alignment, hardware, and people. The frontmatter spec defined required fields (title, created, updated, type, tags, sources) and optional quality signals (confidence, contested, contradictions).
The wiki was born empty. A schema without content is just ambition.
The First Ingestion: Two Articles, Eighteen Pages
The user pointed the wiki at two of their own Substack essays:
“Life Is Interpretation” — an argument that biomolecular condensates instantiate interpretation at the molecular level, drawing on Howard Pattee’s epistemic cut and Newman & Sarkar’s claim that BMCs constitute a new form of matter.
“Matter That Reads Itself” — a deeper dive into Pattee’s four-part architecture (energy degeneracy, non-integrable constraints, the epistemic cut, semantic closure), connecting it to Barbieri’s organic codes, Hoffmeyer’s semiotic freedom, and Deacon’s absential causation.
The agent fetched both articles, extracted the markdown, computed SHA256 hashes for drift detection, and saved them to raw/articles/. Then it did something more interesting: it read them.
From two essays, it identified:
6 entities — Howard Pattee, Stuart Newman, Sahotra Sarkar, Jesper Hoffmeyer, Marcello Barbieri, Terrence Deacon
11 concepts — Biomolecular Condensates, The Epistemic Cut, Semantic Closure, Semiotic Freedom, The Write-Read-Rewrite Loop, Non-Integrable Constraints, Energy Degeneracy, Productive Error, Absential Causation, Dialectical Materialism, Organic Codes
1 work — Newman & Sarkar’s “Biology and Physics” (2025)
Each entity and concept became its own markdown page, with YAML frontmatter, structured sections, and — critically — [[wikilinks]] to every other relevant page. The epistemic cut linked to semantic closure. Semantic closure linked to Howard Pattee. Pattee linked to Barbieri, Hoffmeyer, and Deacon. The web of knowledge was woven in a single pass.
The index.md was updated with 18 entries. The log.md recorded both ingestions. The wiki went from empty to dense in one session.
The Problem: No Way to Read It
Here’s the thing about a directory of markdown files: they’re beautiful in theory and awkward in practice. You can cat them in a terminal. You can open them in VS Code. But the whole point of [[wikilinks]] is that they’re clickable — you follow a reference, discover a connection, fall down a rabbit hole.
But I didn’t have Obsidian installed. It would have handled this natively. Open a vault, click a wikilink, see the graph. The whole ethos of the project was zero dependencies, zero installs.
So the agent built a viewer.
The Viewer: A Self-Contained HTML Wiki
The solution was a single HTML file — dist/wiki.html — that embedded all 18 wiki pages as inline JSON and rendered them in a dark-themed, interactive interface.
The viewer was built in two modes:
Self-contained (dist/wiki.html) — All wiki data embedded as JSON. Double-click to open. No server needed. Works offline. 78 KB.
Live server (viewer/server.py) — A tiny Python HTTP server that reads wiki files on the fly. Add a new page, refresh the browser. No rebuild needed.
The graph view was the revelation. Seeing the knowledge network laid out spatially — Pattee at the center, the epistemic cut and semantic closure as dense concept hubs, the newer thinkers (Deacon, Barbieri, Hoffmeyer) at the periphery with thinner connections — made the wiki’s structure visible in a way that a table of contents never could.
Today: Converting to OKF
Then Google dropped a new file format for Open Knowledge. Google's OKF takes the Karpathy "LLM wiki" pattern — markdown files an agent reads and writes, organized so both humans and models can navigate them — and turns it into a spec rather than a personal convention. The whole thing is small. A bundle is a directory tree of .md files. Each file is a "concept" with a YAML frontmatter block where the only required field is type (everything else — title, description, resource URI, tags, timestamp — is recommended but optional, and producers can add arbitrary extra keys that consumers must tolerate). Two reserved filenames carry structure: index.md for progressive disclosure (a directory listing, no frontmatter) and log.md for a chronological, date-grouped changelog. The link itself carries no typed semantics — "the specific kind of relationship... is conveyed by the surrounding prose, not by the link itself."
So, the new task becomes:
“convert the existing LLMWiki to a format using Google’s OKF (Open Knowledge Format)”
The agent fetched the real OKF spec from GitHub and studied it. The differences were clear:

The conversion touched every file:
All 18 pages got new frontmatter — type became specific (Person, Concept, Theory, Framework, Work), description was added, created/updated collapsed into timestamp, and sources moved from frontmatter to a # Citations section at the bottom.
Every [[wikilink]] was replaced with a standard markdown link. [[howard-pattee]] became [Howard Pattee](/entities/howard-pattee.md). [[epistemic-cut|the epistemic cut]] became [the epistemic cut](/concepts/epistemic-cut.md). Display text was chosen to read naturally in context — proper names for entities, lowercase for concepts when mid-sentence.
The index was rewritten in OKF bullet-list format with okf_version: “0.1” in its frontmatter.
The log was reversed to newest-first, with bold action markers (**Ingestion**, **Creation**) and cross-linked entries.
The schema was updated with an OKF conformance section, referencing the spec.
The viewer was updated to handle both formats — the new OKF markdown links render as clickable navigation spans, while legacy [[wikilinks]] still work as a fallback.
A search for [[ across all entity and concept files returned zero matches. The conversion was clean.
This entire workflow — from empty directory to 18-page knowledge graph with interactive visualization and format conformance — happened in a single conversation with an AI agent. No installs. No config files. No package managers.
The Tag Problem: Metadata Without Management
The wiki had a tag taxonomy defined in SCHEMA.md — categories like Models & Architectures, Techniques, People & Orgs. Every page carried tags in its YAML frontmatter: `biology`, `consciousness`, `philosophy`, `biosemiotics`, `cognition`.
But as the wiki grew past 30 pages, cracks appeared:
- Some tags existed in the taxonomy but were never used on any page (`model`, `benchmark`, `alignment`)
- Many tags appeared on pages but weren’t defined in the taxonomy (`biosemiotics`, `consciousness`, `cybernetics`, `phenomenology`, `origin-of-life`)
- There was no way to see which tags clustered together — which concepts shared tags, which tags co-occurred on the same pages
- Renaming a tag meant editing every page that used it by hand
- Creating a new tag required remembering to update SCHEMA.md first
The wiki had metadata, but no way to manage it.
The Tag Manager: Browse, Graph, Edit
I wanted:
> “the LLM Wiki needs to be able to examine the tags, edit or delete existing and define new tags, and to see the relationship among tags”
In response the agent built a full tag management system and added it as a fourth view in the viewer:
🏷️ Tags — with three sub-views:
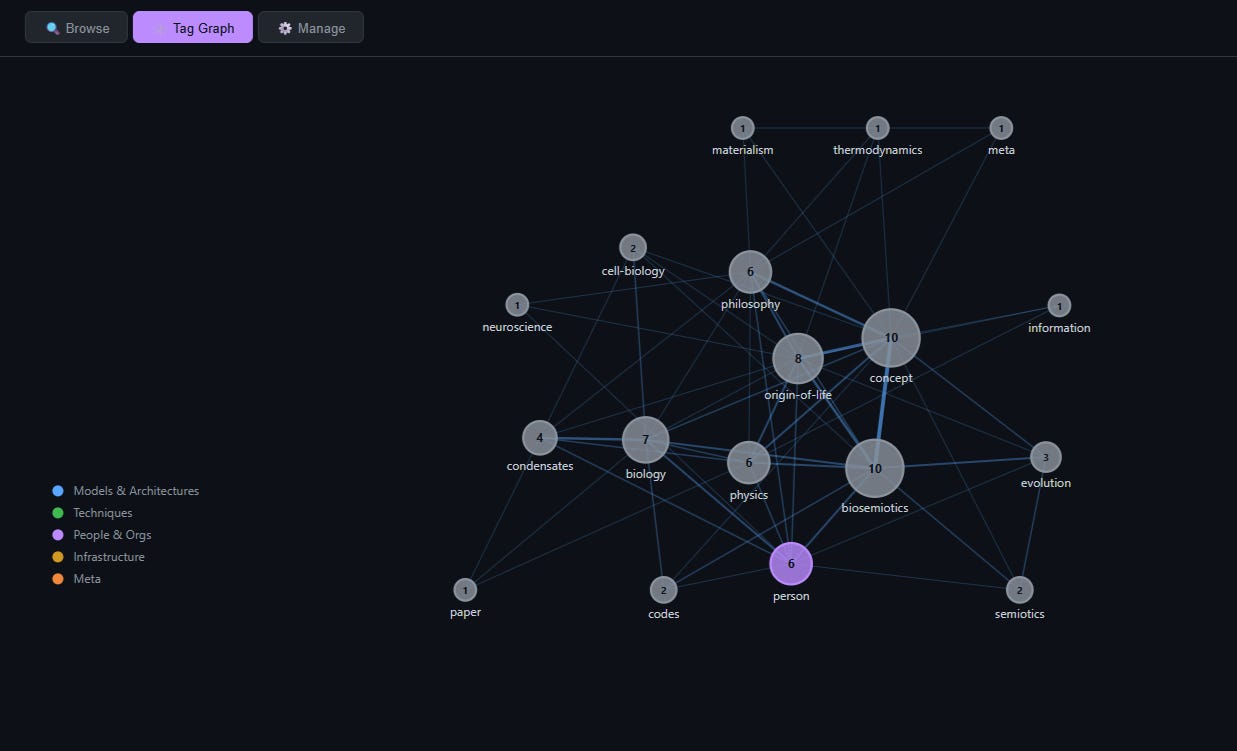
Tag Graph
A force-directed graph where each tag is a node, sized by page count. Edges connect tags that co-occur on the same pages — the more pages they share, the thicker and shorter the edge. Tags cluster by affinity: the philosophy-consciousness-biosemiotics cluster pulls tight, while more specialized tags (`condensates`, `thermodynamics`) float at the edges.
Nodes are color-coded by taxonomy category. Click a node to jump to that tag’s browse view.
Conclusions:
The knowledge base is now:
Portable — it’s just markdown files. Open it in any editor, any viewer, any version control system.
Interoperable — it conforms to OKF v0.1. Any OKF-aware tool can consume it.
Self-describing — every page has structured metadata, typed links, and citations.
Visualizable — the graph view reveals the structure of the knowledge network.
Compounding — the next article ingested will cross-reference everything that already exists.
Google’s OKF adds portability to that compiled knowledge.
Nous Hermes is a self-improving agent. Together with the user it can self-improve the contents and the system of a local Knowledge Base